Why the Best AI Agents Improve From Production Feedback, Not Just Model Upgrades
If you want better AI results, do not just wait for the next model release. Build feedback loops around the work so the system improves from real jobs, real corrections, and real business outcomes.

Tobias Holmgren
Practical AI agents, automation workflows, and reviewed business systems.
Published Jun 12, 2026
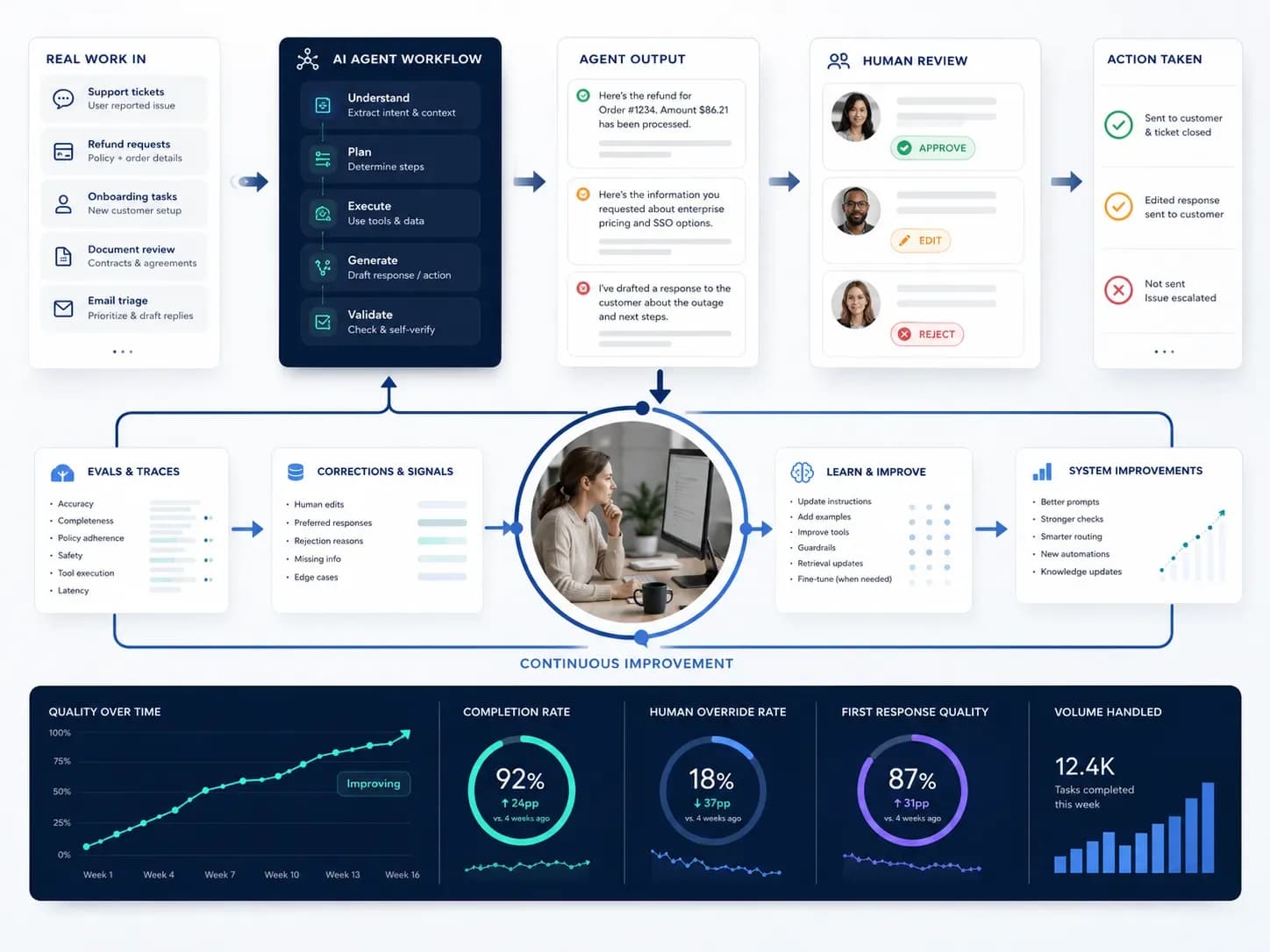
A lot of teams still think better AI means waiting for the next model release. That is becoming less true. The more useful systems are starting to improve because they learn from real work: where they got stuck, what a human corrected, which steps created rework, and which outputs actually helped the business move faster.
That is a much more important shift than it sounds. It means the advantage is moving away from demo quality alone and toward feedback loops, structured traces, human review, and workflow-level measurement.
The next useful AI systems will not win only because the model got smarter. They will win because the workflow keeps teaching the system what good work looks like.
Key takeaways
The best production AI systems improve from feedback loops, not just from bigger models.
Traces, evals, and human corrections turn vague AI experimentation into measurable workflow improvement.
Businesses should review where an agent gets stuck, where people override it, and which outputs actually create downstream value.
This is relevant beyond software teams: finance, operations, support, and internal workflows all benefit from learning from production work.
If you only compare model benchmarks, you may miss the bigger operational advantage.
What this means in simple terms
A normal chatbot session starts fresh every time. A useful production workflow should get smarter over time. Not by magically retraining itself in secret, but by capturing signals from the work itself.
Those signals can be simple: which answer a reviewer approved, which output had to be rewritten, which exception path appeared often, or which steps caused delays. Once you collect those signals, you can improve prompts, tools, routing rules, approval thresholds, and evaluation checks.
Why this matters for business
This matters because most buyers are still judging AI the wrong way. They ask whether the model is impressive. A better question is whether the system gets better after 100 real jobs, 1,000 real jobs, and a month of human review.
The work becomes more reliable instead of staying stuck at first-draft quality.
Teams reduce hidden cleanup and override work.
The system becomes easier to trust because improvement is observable, not mystical.
Performance discussions move from opinions to evidence.
That is when AI starts looking less like a novelty and more like an operating capability.
What production feedback actually looks like
Production feedback does not need to mean complex machine learning infrastructure on day one. In many companies it starts with a reviewed workflow and a simple set of questions after each run.
Did the agent finish the job or hand it back?
Where did a human intervene?
What kind of correction was needed?
Was the output usable in the next workflow step?
Would the same failure likely happen again?
When you answer those questions consistently, patterns appear quickly. You may find that the model is not the main issue at all. Maybe the input data is too messy. Maybe the handoff instructions are weak. Maybe the agent needs a clearer escalation rule. Maybe the review threshold is too low.
What teams often focus on | What improves results faster |
|---|---|
Trying a newer model every week | Studying where the workflow fails in production |
One-off prompt tweaks | Keeping a record of recurring corrections |
Demo outputs | Reviewed outputs that reached the next business step |
General benchmark scores | Task-specific evals tied to business outcomes |
How clever the agent sounds | How reliably the workflow finishes with low cleanup |
A practical example business leaders can understand
OpenAI's recent tax-agent example is useful because it gives a business-readable picture of this shift. The point is not tax specifically. The point is that a real agent system improves when the team studies traces, failure modes, review outcomes, and task-level evals from production work.
That is how you move from the agent can sometimes do the task to the workflow usually reaches a reliable standard. In practice, the team is learning which tool calls work, which instructions need tightening, which edge cases need routing, and what human reviewers consistently care about.
Business owners should read that as a general lesson: the real moat is often not access to the model. It is the quality of the workflow learning loop around the model.
The operating model behind self-improving agents
If I were designing this for a business workflow, I would think about five layers.
Clear task boundary: know exactly what the agent is supposed to finish.
Traceability: record the steps, inputs, tool use, and handoff points.
Human review: capture what was accepted, corrected, rejected, or escalated.
Task-specific evals: measure quality against the real standard for the job.
Iteration loop: update prompts, rules, tools, and approvals based on recurring evidence.
Start with one repeated workflow
Choose a process that happens often enough to generate learning: support triage, lead qualification, meeting follow-up, quote drafting, or internal research summaries. A feedback loop is hard to build around work that rarely repeats.
Where teams get this wrong
There are three common mistakes I keep seeing.
1. They treat every failure as a model problem
Sometimes the model is the problem. Often it is not. Weak instructions, poor source data, missing approvals, and unclear success criteria are usually easier to fix and often matter more.
2. They collect activity but not learning
A log file is not a feedback loop. You need a way to tag what went wrong, what a human changed, and whether the output was good enough for the next step.
3. They optimize for speed before reliability
If you scale a workflow before you understand the failure pattern, you usually scale rework. Reliability first. Then volume.
Pros and cons of this approach
Pros
Creates durable improvement instead of repeating the same mistakes.
Builds a stronger business case because the gains can be measured over time.
Helps teams trust AI through evidence, not hype.
Cons
Needs workflow discipline, not just enthusiasm for AI.
Requires review design and clear ownership.
Can feel slower at the start than chasing flashy demos.
How to start small
Pick one recurring workflow with clear inputs and outputs.
Add a lightweight review step so people can approve, edit, or reject the output.
Track the most common corrections for two to four weeks.
Turn those corrections into prompt updates, routing rules, or new eval checks.
Review whether the workflow now finishes faster, cleaner, or with fewer escalations.
That is enough to prove the principle. You do not need a giant AI platform to learn from the work. You need a repeatable process and the discipline to study it.
FAQ
Does this only matter for technical teams?
No. Any repeated workflow can benefit from feedback loops: operations, support, sales follow-up, finance review, content production, and internal reporting.
Does learning from production work mean retraining the model?
Not necessarily. In many cases the first gains come from better prompts, routing, tools, review thresholds, and evals rather than full model retraining.
What should a business measure first?
Start with workflow completion rate, human override rate, correction categories, exception volume, and whether the output was usable in the next step.
Final takeaway
The next generation of useful AI systems will be shaped less by who talks most loudly about the model and more by who builds the best learning loop around the work.
That is good news for practical businesses. It means the opportunity is not reserved for whoever has the biggest lab. It belongs to teams that understand their workflow, capture feedback, and improve the system step by step.